Create: Update:
چطور DeepSeek R1 سرعت و کارایی رو با هم افزایش داد؟
واسه جواب دادن به این سوال این کلیپ یوتیوب رو پیشنهاد میکنم ببینید: لینک
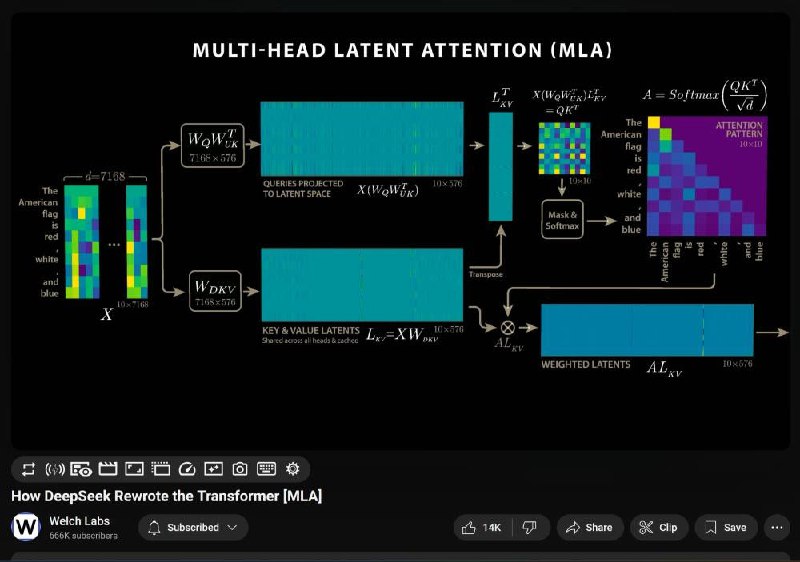
تو این ویدیو، روش جدیدی به نام «Multi-Head Latent Attention» (MHLA) معرفی میشه که با کاهش مصرف حافظه، سرعت استنتاج رو افزایش میده.
همینطور گفته میشه کهDeepSeek R1 موفق شده اندازه «Key-Value Cache» (کش KV) را ۵۷ برابر کاهش بده و تولید متن رو ۶ برابر سریعتر از ترنسفورمرهای سنتی انجام بده
منم سعی میکنم به زودی یه خلاصه ای از عملکرد و این روشو بگم
@silicon_brain | از هوش مصنوعی عقب نمانید

>>Click here to continue<<
Silicon Brain | جامعه هوش مصنوعی