Create: Update:
Тензерирование или быстрая загрузка весов моделей в GPU
Раскроем подробнее что такое Тензерирование - это способ сериализации и десериализации весов модели, что позволяет сократить время загрузки весов в GPU. Также позволяет загружать веса в S3, добавить шифрование, уменьшить время старта инференса и нагрузку на CPU.
Истоки - Проект CoreWeave
Как добавили в VLLM
Как использовать в VLLM
Пример скрипта сериализации/десериализации. В комментах подробные инструкции как пользоваться.
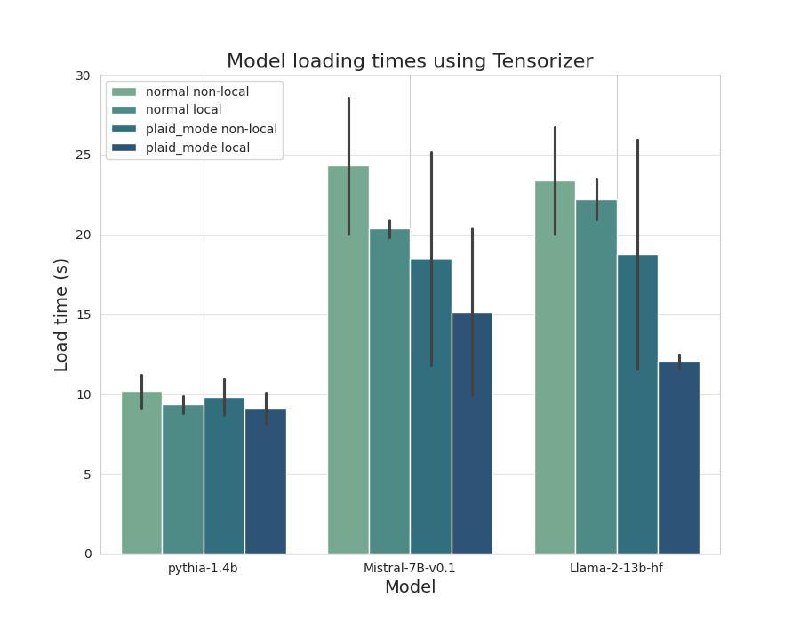
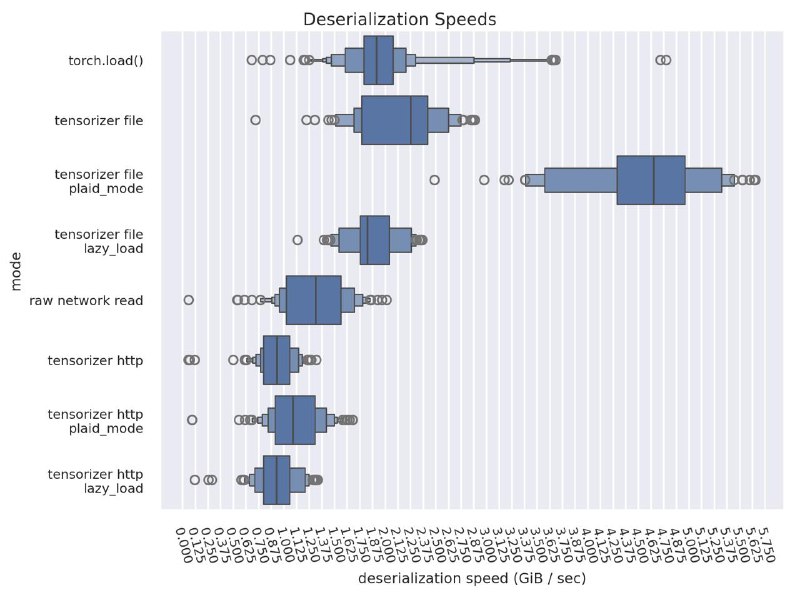
Результаты тестирования
Замерял время загрузки весов из local path в GPU во время старта VLLM
Qwen3-8b
A100 40gb x1
веса размером 15.2683 GiB
tensorize vs default
5.435905 sec vs 34.538318 sec
пример конфига для vllm
Разница в 7 раз
Qwen3-32b
A100 40gb x2 при tensor-parallel-size 2
Веса размером 30.5855 GiB
tensorize vs default
118.667568 sec vs 307.285575 sec
пример конфига для vllm
Разница в 3 раза
Загружаются веса действительно в разы быстрее. У кого стоит задача уменьшить время загрузки весов в GPU - рекомендую присмотреться к этому способу!
Раскроем подробнее что такое Тензерирование - это способ сериализации и десериализации весов модели, что позволяет сократить время загрузки весов в GPU. Также позволяет загружать веса в S3, добавить шифрование, уменьшить время старта инференса и нагрузку на CPU.
Истоки - Проект CoreWeave
Как добавили в VLLM
Как использовать в VLLM
Пример скрипта сериализации/десериализации. В комментах подробные инструкции как пользоваться.
Результаты тестирования
Замерял время загрузки весов из local path в GPU во время старта VLLM
Qwen3-8b
A100 40gb x1
веса размером 15.2683 GiB
tensorize vs default
5.435905 sec vs 34.538318 sec
пример конфига для vllm
{
"model":"Qwen/Qwen3-8B",
"load_format": "tensorizer",
"model_loader_extra_config": {"tensorizer_uri": "/root/models/ser-qwen-from-local/vllm/qwen_hf/v1/model.tensors"}
}
Разница в 7 раз
Qwen3-32b
A100 40gb x2 при tensor-parallel-size 2
Веса размером 30.5855 GiB
tensorize vs default
118.667568 sec vs 307.285575 sec
пример конфига для vllm
{
"model":"Qwen/Qwen3-32B",
"load_format": "tensorizer",
"model_loader_extra_config": {
"tensorizer_uri": "/root/models/ser-qwen-32-from-local/vllm/qwen_32/v1/model-rank-%03d.tensors"
},
"tensor_parallel_size": 2,
"disable_log_requests": "true",
"gpu_memory_utilization": 0.9,
"max_model_len": 5024
}
Разница в 3 раза
Загружаются веса действительно в разы быстрее. У кого стоит задача уменьшить время загрузки весов в GPU - рекомендую присмотреться к этому способу!

Forwarded from Anton Alekseev | Инфраструктура для AI и ML
Тензерирование или быстрая загрузка весов моделей в GPU
Раскроем подробнее что такое Тензерирование - это способ сериализации и десериализации весов модели, что позволяет сократить время загрузки весов в GPU. Также позволяет загружать веса в S3, добавить шифрование, уменьшить время старта инференса и нагрузку на CPU.
Истоки - Проект CoreWeave
Как добавили в VLLM
Как использовать в VLLM
Пример скрипта сериализации/десериализации. В комментах подробные инструкции как пользоваться.
Результаты тестирования
Замерял время загрузки весов из local path в GPU во время старта VLLM
Qwen3-8b
A100 40gb x1
веса размером 15.2683 GiB
tensorize vs default
5.435905 sec vs 34.538318 sec
пример конфига для vllm
Разница в 7 раз
Qwen3-32b
A100 40gb x2 при tensor-parallel-size 2
Веса размером 30.5855 GiB
tensorize vs default
118.667568 sec vs 307.285575 sec
пример конфига для vllm
Разница в 3 раза
Загружаются веса действительно в разы быстрее. У кого стоит задача уменьшить время загрузки весов в GPU - рекомендую присмотреться к этому способу!
Раскроем подробнее что такое Тензерирование - это способ сериализации и десериализации весов модели, что позволяет сократить время загрузки весов в GPU. Также позволяет загружать веса в S3, добавить шифрование, уменьшить время старта инференса и нагрузку на CPU.
Истоки - Проект CoreWeave
Как добавили в VLLM
Как использовать в VLLM
Пример скрипта сериализации/десериализации. В комментах подробные инструкции как пользоваться.
Результаты тестирования
Замерял время загрузки весов из local path в GPU во время старта VLLM
Qwen3-8b
A100 40gb x1
веса размером 15.2683 GiB
tensorize vs default
5.435905 sec vs 34.538318 sec
пример конфига для vllm
{
"model":"Qwen/Qwen3-8B",
"load_format": "tensorizer",
"model_loader_extra_config": {"tensorizer_uri": "/root/models/ser-qwen-from-local/vllm/qwen_hf/v1/model.tensors"}
}
Разница в 7 раз
Qwen3-32b
A100 40gb x2 при tensor-parallel-size 2
Веса размером 30.5855 GiB
tensorize vs default
118.667568 sec vs 307.285575 sec
пример конфига для vllm
{
"model":"Qwen/Qwen3-32B",
"load_format": "tensorizer",
"model_loader_extra_config": {
"tensorizer_uri": "/root/models/ser-qwen-32-from-local/vllm/qwen_32/v1/model-rank-%03d.tensors"
},
"tensor_parallel_size": 2,
"disable_log_requests": "true",
"gpu_memory_utilization": 0.9,
"max_model_len": 5024
}
Разница в 3 раза
Загружаются веса действительно в разы быстрее. У кого стоит задача уменьшить время загрузки весов в GPU - рекомендую присмотреться к этому способу!
>>Click here to continue<<
Data Science by ODS.ai 🦜