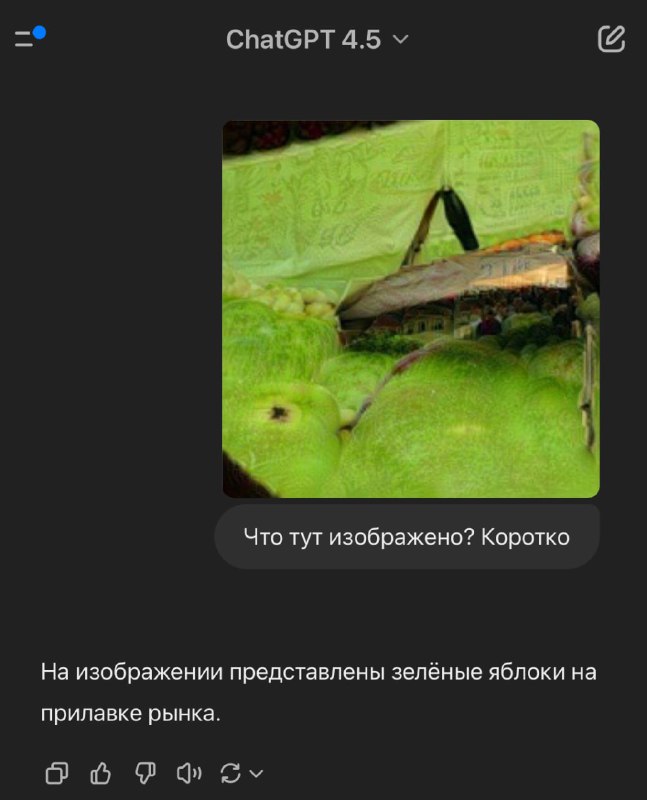
M-Attack: как обмануть GPT-4.5 и Gemini
Все привыкли, что атаковать современные мультимодальные модели (типа GPT-4o, Claude, Gemini и т.п.) крайне сложно — особенно, если это black-box модели, где нет доступа к градиентам и архитектуре. Стандартные подходы атак типа "выдать одну картинку за другую" часто генерируют какие-то невнятные шумы, которые либо игнорируются моделью, либо приводят к абстрактным ответам типа "размытое изображение".
Но оказалось, что проблема была не в самих моделях, а в подходе к генерации возмущений. В свежей статье предложили очень простой, но мощный подход — M-Attack:
1. Берём исходную и целевую картинки.
2. На каждом шаге рандомно crop'аем кусок исходного изображения (50-100% площади) и затем ресайзим обратно до исходного размера.
3. Заставляем эмбеддинги этого кусочка максимально приблизиться к эмбеддингам целевого изображения оптимизируясь в white-box режиме по ансамблю открытых визуальных моделей (например, CLIP, ViT и тп).
И всё! После нескольких итераций в центральной области картинки "проявляется" целевая семантика, при этом возмущения выглядят крайне незаметно и аккуратно (в отличие от других подходов).
Авторы добились совершенно впечатляющих результатов: успех атаки (ASR) превышает 90% (!) для GPT-4.5, GPT-4o и даже для o1 и Gemini. Код и датасет из 100 атакованных картинок выложили в открытый доступ.
Статья, GitHub, dataset

>>Click here to continue<<