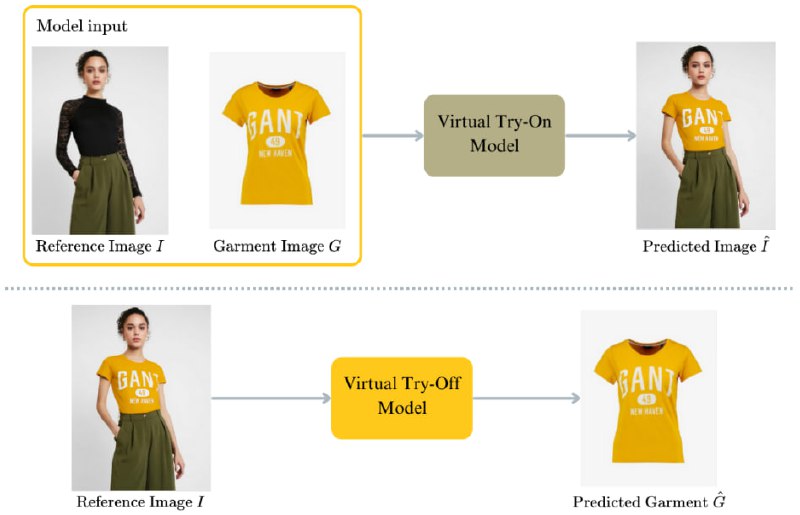
Как человек, увлечённый развитием Fashion Tech и применением компьютерного зрения в индустрии моды, я внимательно слежу за новыми направлениями и подходами. Всем уже привычна задача Virtual Try-On (VTON), когда нейросети (диффузионные модели в данный момент) виртуально примеряют одежду на изображениях людей. Однако сейчас набирает популярность противоположное направление — Virtual Try-Off (VTOFF), задача извлечения одежды с моделей и получения её канонического изображения. Это не просто новая фишка, а перспективная задача с серьёзными техническими вызовами: в отличие от традиционного VTON, где модель цифровым образом «одевается», VTOFF стремится выделить и «снять» одежду, сохранив при этом её точную форму, текстуру и даже сложные паттерны ткани.
Кстати, на идущей прямо сейчас конференции CVPR-2025 были приняты пейперы, посвящённые именно Virtual Try-Off.
Зачем индустрии моды такой подход?
1. Создание идеального каталога — возможность быстро получить идеализированное изображение одежды, свободное от складок, позы и особенностей модели.
2. Точная визуализация и кастомизация — одежда, полученная через VTOFF, может быть легко переиспользована и виртуально адаптирована к новым условиям (поза, модель, фон).
3. Повышение эффективности производства контента — сокращение затрат на новые фотосессии и обработку изображений.
Вот пара интересных подхода к задаче Virtual Try-Off, которые стоит изучить уже сейчас:
TryOffDiff: Virtual Try-Off via High-Fidelity Garment Reconstruction using Diffusion Models
Основная цель: получить оригинальное изображение одежды (без тела, позы и искажений) из одной фотографии одетого человека.
Ключевые идеи:
TryOffAnyone: Tiled Cloth Generation from a Dressed Person
Основная цель: восстановить канонический вид одежды с фото одетого человека, представив её в виде тайлов (фрагментов), пригодных для переиспользования и редактирования.
Ключевые идеи:
Оба подхода — TryOffDiff и TryOffAnyone — подчёркивают, что Virtual Try-Off нельзя рассматривать как простое дополнение к VTON. Это отдельный класс задач, требующий других архитектурных решений, способных восстанавливать геометрию, структуру и текстильные особенности одежды в отрыве от тела, позы и сцены.
@sonya_aesthetics
Create: Update:

>>Click here to continue<<
Пресидский залив (ex Надя пробует)
Share with your best friend
VIEW MORE