Обслуживание LLMс архитектурой MoE всегда было сложной задачей: несмотря на снижение вычислительной нагрузки за счёт «разреженной» активации экспертов, GPU часто простаивают из-за неэффективного распределения ресурсов.
Новая методика MegaScale-Infer от ByteDance|Seed предлагает разделение модулей внимания и feed-forward networks (FFN) на независимые узлы с индивидуальной оптимизацией. Это не только делает загрузку GPU эффективной, но и сокращает стоимость обслуживания моделей в 1,9 раза по сравнению с аналогами.
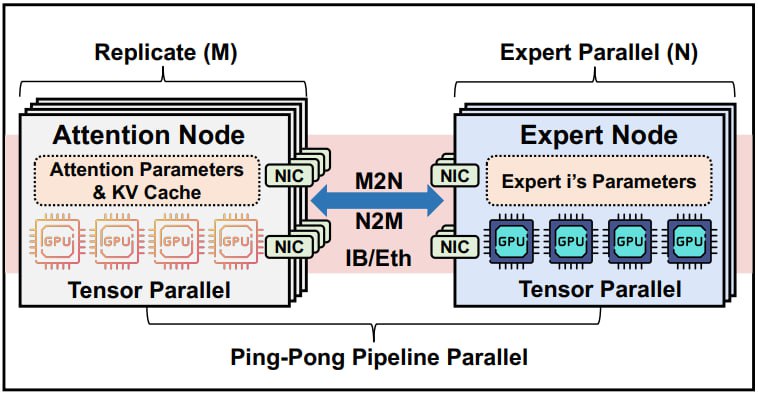
Суть MegaScale-Infer — в «дизагрегации»: модули внимания, отвечающие за работу с ключевыми значениями (KV-кэш), и FFN-эксперты распределяются по разным GPU. Например, узлы внимания можно развернуть на GPU с высокой пропускной способностью памяти, а эксперты — на устройствах с мощными вычислительными ядрами. Такой подход позволяет масштабировать каждый компонент отдельно и избежать дисбаланса, когда один модуль ждет завершения работы другого.
Чтобы скрыть задержки связи между узлами, система использует конвейерный параллелизм. Запросы разбиваются на микропакеты, которые перекидываются между модулями внимания и FFN, как мячик в пинг-понге. Это минимизирует простои: пока один микропакет обрабатывается экспертами, механизмы внимания на GPU уже начинают работать со следующим.
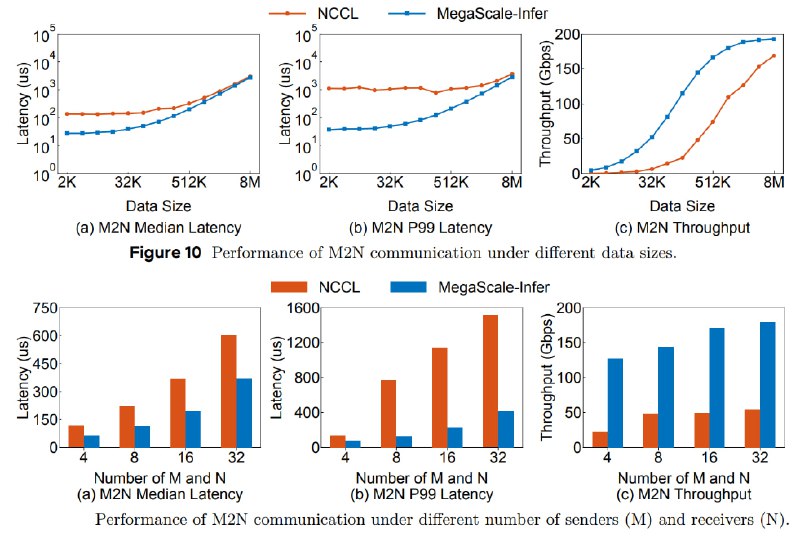
Для стабильной коммуникации между сотнями устройств разработана библиотека M2N — она ускоряет передачу данных в 4,2 раза по сравнению с NCCL, устраняя лишние копии данных и синхронизацию.
Эксперименты на моделях Mixtral 8x22B (141 млрд. параметров) и DBRX (132 млрд.) показали, что MegaScale-Infer обрабатывает до 2,56Х больше токенов в секунду на один GPU, чем vLLM и TensorRT-LLM.
На гетерогенных кластерах с GPU H20 (для внимания) и L40S (для экспертов) система демонстрирует еще больший эффект: стоимость генерации токена снижается в 1,86 раза за счет оптимального распределения ресурсов: H20, обладая огромной памятью, идеально подходят для работы с KV-кэшем, а L40S эффективно считают матричные операции в FFN.
Для разработчиков, которые работают с LLM, MegaScale-Infer — не просто еще один фреймворк. Это инструмент, который превращает MoE-модели из ресурсоемких «монстров» в управляемые системы, где каждый GPU работает на пределе возможностей.
@ai_machinelearning_big_data
#AI #ML #LLM #MLOPS #MegaScaleInfer #ByteDance
Create: Update:

>>Click here to continue<<
Neural Networks | Нейронные сети


Share with your best friend
VIEW MORE