Create: Update:
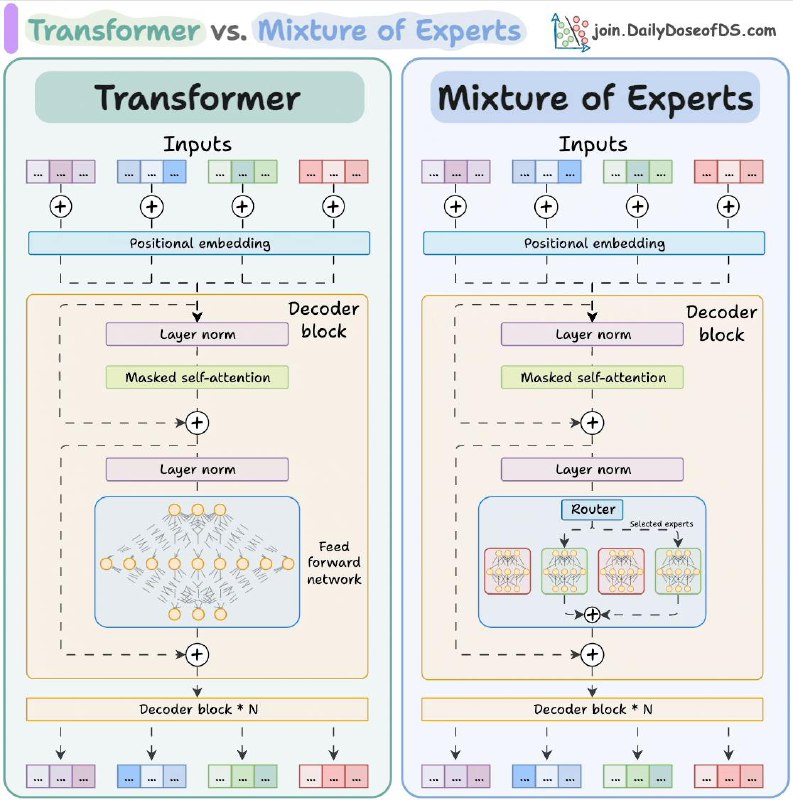
В обоих случаях есть базовые элементы вроде входных эмбеддингов, механизмов самовнимания (self-attention) и последовательного наложения блоков (N слоёв), но в «Mixture of Experts» внутри каждого блока появляется «router» (маршрутизатор).
Этот маршрутизатор решает, какие «эксперты» (специализированные подмодули) должны обработать текущие данные.
Таким образом, в отличие от обычного Transformer’а, где у нас один набор весов на слой, в «Mixture of Experts» несколько разных «экспертов» конкурируют или дополняют друг друга для более гибкой и точной обработки информации.