Create: Update:
🚀 Deep Seek представили NSA – инновационную Sparse Attention технологию для ультрабыстрого обучения и инференса с длинным контекстом!
Основные детали:
• Динамическая иерархическая разреженность – модель умело распределяет внимание, выделяя ключевые моменты в длинных последовательностях.
• Грубое сжатие токенов – снижает объём обрабатываемых данных без потери важной информации.
• Точный выбор токенов – сохраняет критически значимые детали для высокой точности.
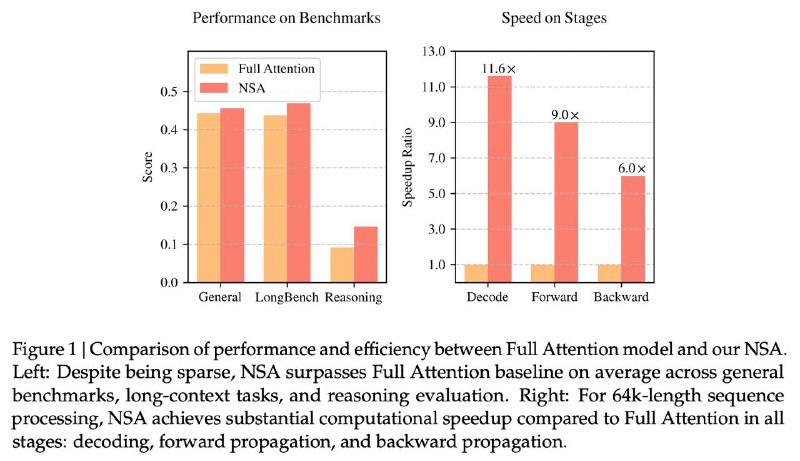
Благодаря оптимизации под современное железо NSA не только ускоряет инференс, но и снижает затраты на предобучение, при этом демонстрируя результаты, сравнимые или превосходящие Full Attention модели на общих тестах, задачах с длинным контекстом и инструктивном рассуждении.
Подробности и технические детали в статье: https://arxiv.org/abs/2502.11089
@machinelearning_interview
Основные детали:
• Динамическая иерархическая разреженность – модель умело распределяет внимание, выделяя ключевые моменты в длинных последовательностях.
• Грубое сжатие токенов – снижает объём обрабатываемых данных без потери важной информации.
• Точный выбор токенов – сохраняет критически значимые детали для высокой точности.
Благодаря оптимизации под современное железо NSA не только ускоряет инференс, но и снижает затраты на предобучение, при этом демонстрируя результаты, сравнимые или превосходящие Full Attention модели на общих тестах, задачах с длинным контекстом и инструктивном рассуждении.
Подробности и технические детали в статье: https://arxiv.org/abs/2502.11089
@machinelearning_interview

🚀 Deep Seek представили NSA – инновационную Sparse Attention технологию для ультрабыстрого обучения и инференса с длинным контекстом!
Основные детали:
• Динамическая иерархическая разреженность – модель умело распределяет внимание, выделяя ключевые моменты в длинных последовательностях.
• Грубое сжатие токенов – снижает объём обрабатываемых данных без потери важной информации.
• Точный выбор токенов – сохраняет критически значимые детали для высокой точности.
Благодаря оптимизации под современное железо NSA не только ускоряет инференс, но и снижает затраты на предобучение, при этом демонстрируя результаты, сравнимые или превосходящие Full Attention модели на общих тестах, задачах с длинным контекстом и инструктивном рассуждении.
Подробности и технические детали в статье: https://arxiv.org/abs/2502.11089
@machinelearning_interview
Основные детали:
• Динамическая иерархическая разреженность – модель умело распределяет внимание, выделяя ключевые моменты в длинных последовательностях.
• Грубое сжатие токенов – снижает объём обрабатываемых данных без потери важной информации.
• Точный выбор токенов – сохраняет критически значимые детали для высокой точности.
Благодаря оптимизации под современное железо NSA не только ускоряет инференс, но и снижает затраты на предобучение, при этом демонстрируя результаты, сравнимые или превосходящие Full Attention модели на общих тестах, задачах с длинным контекстом и инструктивном рассуждении.
Подробности и технические детали в статье: https://arxiv.org/abs/2502.11089
@machinelearning_interview
👍17🔥4❤3🤩1
>>Click here to continue<<
Machine learning Interview