Microsoft Research представила методы, усиливающие способность языковых моделей, от компактных до гигантских к сложным рассуждениям. Технологии фокусируются на 3 направлениях: архитектура малых моделей, математическая строгость и кросс-доменное обобщение.
Ключ для маленьких моделей (1.5–7 млрд параметров) в имитации человеческого пошагового мышления.
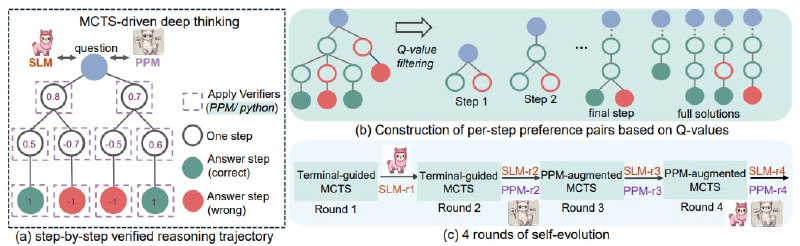
rStar-Math использует алгоритм MCTS в цикле самообучения: сначала декомпозиция задачи на шаги, затем Process Preference Model (PPM), который учит модель оценивать качество каждого шага через "метки награды", и наконец — итеративная доработка. За 4 цикла MCTS, стратегия и PPM совместно улучшают результат.
Logic-RL — это фреймворк обучения с подкреплением, который награждает модель только при идеально оформленном ходе рассуждений и верном ответе, исключая любые попытки выбора обходных путей.
Для математической надежности разработан LIPS, гибрид ИИ и символьных движков. LIPS распределяет задачи: языковая модель распознает паттерны и переформулирует условия (например, неравенства), а символьный решатель выполняет точные преобразования (масштабирование, упрощение).
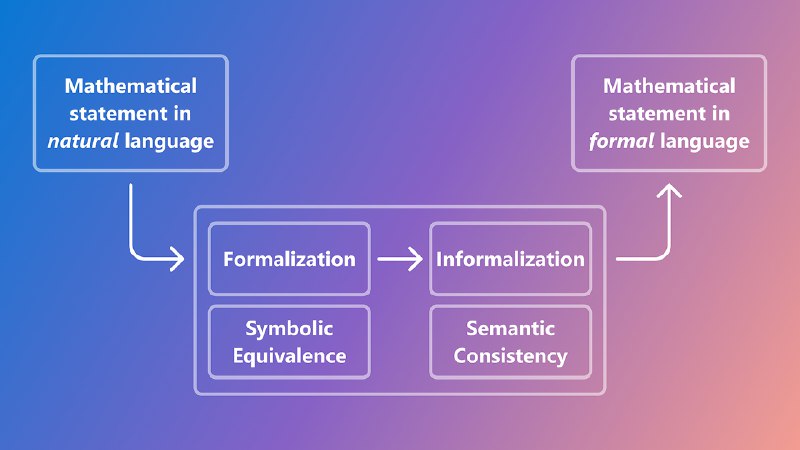
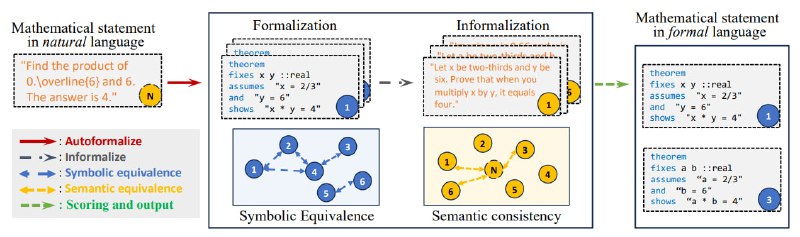
Чтобы ИИ понимал условия без ошибок, создан нейро-символический фреймворк генерации данных: символьные системы создают задачи, а языковые модели переводят их в "человеческий" текст. Для проверки выводов используются символьная эквивалентность (сравнение формул) и семантическая согласованность (анализ смысла через эмбеддинги), повышая точность на 35%.
Дополнительный бонус — неожиданное обобщение. Тренировка на математике резко улучшила результаты моделей в программировании и естественных науках.
Для унификации подходов создан Chain-of-Reasoning (CoR), позволяющий гибко комбинировать текстовые, программные и символьные рассуждения в одном решении. А Critical Plan Step Learning (CPL) учит ИИ стратегическому планированию: разбивать проблему, выделять ключевые шаги и отбрасывать слабые варианты через комбинацию Plan-based MCTS и Step-APO.
@ai_machinelearning_big_data
#AI #ML #LLM #RL #Reasoning #Microsoft
Create: Update:

>>Click here to continue<<
Машиннное обучение | Наука о данных Библиотека

Share with your best friend
VIEW MORE