Create: Update:
Понимают ли большие языковые модели данные из таблиц? (ссылка на хабр)
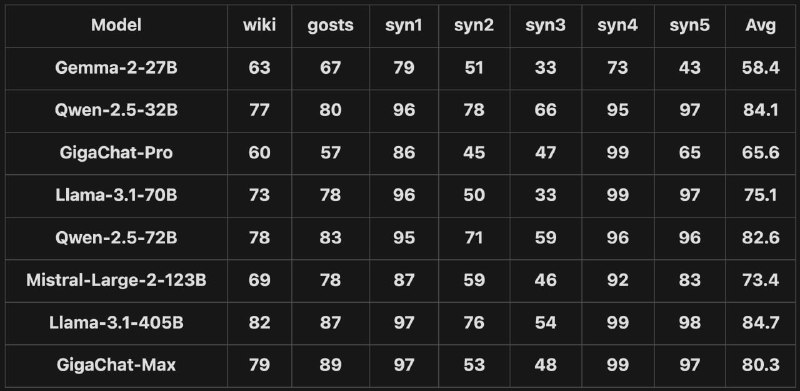
Наши коллеги из команды IDP (Intelligent Document Processing) провели серию тестов различных LLM (среди них есть GigaChat MAX) на то, как они справляются с обработкой табличных данных. Подробности методики проведения замеров можно узнать ниже, а сами результаты на в приложенной картинке.
Главная задача модели при работе с таблицами — понимать связь между разными столбцами и строками. Для проверки этой способности нам нужно было создать вопрос, который бы требовал анализа хотя бы нескольких пар строк или столбцов.
Мы выбрали самую естественную и частотную (что также подтверждалось статистикой по нашему проекту) структуру вопроса: «Какое значение будет в столбце target, если в столбце query стоит число X?»
Это если вкратце, а для полного ознакомления с исследованием предлагаем погрузиться в статью!

>>Click here to continue<<
GigaDev — разработка GigaChat