Create: Update:
🔥 Как FP8-вычисления ускоряют обучение больших моделей?
Когда-то переход на FP16 в машинном обучении был настоящим вызовом — приходилось бороться с переполнением чисел, потерей точности и нестабильностью тренировки. Со временем появился BF16, который совместил в себе диапазон FP32 и компактность FP16, сильно упростив работу и удешевив обучение моделей.
Но прогресс не стоит на месте: хочется использовать ещё более компактный тип FP8, который может ускорить вычисления теоретически аж в 4 раза по сравнению с FP32.
Звучит круто, но на практике есть сложности: FP8 бывает разным. Самые распространённые форматы:
🔸 E4M3 — шире диапазон чисел, ниже точность (подходит для активаций)
🔸 E5M2 — точнее числа, но уже диапазон (лучше для весов)
Из-за того, что в FP8 всего 8 бит на число, быстро возникают проблемы переполнения или, наоборот, слишком сильного округления. Поэтому использовать FP8 напрямую для всех операций пока невозможно. Нужно хитро подбирать форматы и аккуратно контролировать масштаб данных.
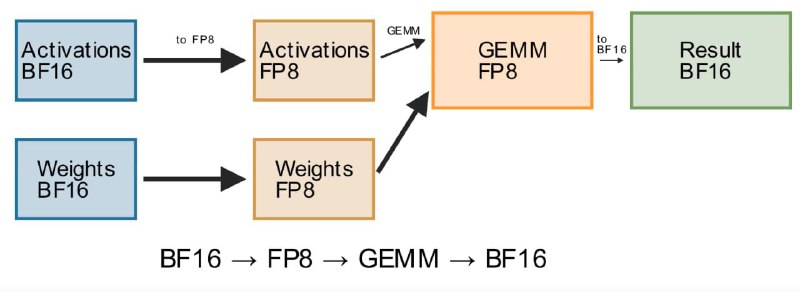
В GigaChat мы начали внедрять FP8 постепенно, сфокусировавшись сначала на наиболее подходящей для него операции — перемножении матриц (GEMM). Но даже здесь возникли свои сложности: активации и веса всё ещё хранятся в BF16, а значит, каждую операцию нужно предварять конвертацией типов:
активации (BF16) → FP8
веса (BF16) → FP8
перемножение матриц в FP8
результат (FP8) → обратно в BF16
Без специальных оптимизаций эти постоянные преобразования приводят к огромным накладным расходам. И именно здесь критически важен
Несмотря на сложности, мы уже смогли ускорить тренировку на впечатляющие 27%, полностью сохранив точность модели 🚀
Что можно делать дальше:
🔸 Сократить количество BF16-активаций там, где это возможно без потери качества
🔸 Переводить межузловые коммуникации на FP8
⚡️Будем держать вас в курсе следующих оптимизаций! Stay tuned
P.S. Большое спасибо GigaChat Max 2.0 за анимацию!
Когда-то переход на FP16 в машинном обучении был настоящим вызовом — приходилось бороться с переполнением чисел, потерей точности и нестабильностью тренировки. Со временем появился BF16, который совместил в себе диапазон FP32 и компактность FP16, сильно упростив работу и удешевив обучение моделей.
Но прогресс не стоит на месте: хочется использовать ещё более компактный тип FP8, который может ускорить вычисления теоретически аж в 4 раза по сравнению с FP32.
Звучит круто, но на практике есть сложности: FP8 бывает разным. Самые распространённые форматы:
🔸 E4M3 — шире диапазон чисел, ниже точность (подходит для активаций)
🔸 E5M2 — точнее числа, но уже диапазон (лучше для весов)
Из-за того, что в FP8 всего 8 бит на число, быстро возникают проблемы переполнения или, наоборот, слишком сильного округления. Поэтому использовать FP8 напрямую для всех операций пока невозможно. Нужно хитро подбирать форматы и аккуратно контролировать масштаб данных.
В GigaChat мы начали внедрять FP8 постепенно, сфокусировавшись сначала на наиболее подходящей для него операции — перемножении матриц (GEMM). Но даже здесь возникли свои сложности: активации и веса всё ещё хранятся в BF16, а значит, каждую операцию нужно предварять конвертацией типов:
активации (BF16) → FP8
веса (BF16) → FP8
перемножение матриц в FP8
результат (FP8) → обратно в BF16
Без специальных оптимизаций эти постоянные преобразования приводят к огромным накладным расходам. И именно здесь критически важен
torch.compile: он автоматически объединяет цепочки таких операций, избавляясь от ненужных промежуточных шагов и резко снижая задержки и копирования.Несмотря на сложности, мы уже смогли ускорить тренировку на впечатляющие 27%, полностью сохранив точность модели 🚀
Что можно делать дальше:
🔸 Сократить количество BF16-активаций там, где это возможно без потери качества
🔸 Переводить межузловые коммуникации на FP8
⚡️Будем держать вас в курсе следующих оптимизаций! Stay tuned
P.S. Большое спасибо GigaChat Max 2.0 за анимацию!

🔥 Как FP8-вычисления ускоряют обучение больших моделей?
Когда-то переход на FP16 в машинном обучении был настоящим вызовом — приходилось бороться с переполнением чисел, потерей точности и нестабильностью тренировки. Со временем появился BF16, который совместил в себе диапазон FP32 и компактность FP16, сильно упростив работу и удешевив обучение моделей.
Но прогресс не стоит на месте: хочется использовать ещё более компактный тип FP8, который может ускорить вычисления теоретически аж в 4 раза по сравнению с FP32.
Звучит круто, но на практике есть сложности: FP8 бывает разным. Самые распространённые форматы:
🔸 E4M3 — шире диапазон чисел, ниже точность (подходит для активаций)
🔸 E5M2 — точнее числа, но уже диапазон (лучше для весов)
Из-за того, что в FP8 всего 8 бит на число, быстро возникают проблемы переполнения или, наоборот, слишком сильного округления. Поэтому использовать FP8 напрямую для всех операций пока невозможно. Нужно хитро подбирать форматы и аккуратно контролировать масштаб данных.
В GigaChat мы начали внедрять FP8 постепенно, сфокусировавшись сначала на наиболее подходящей для него операции — перемножении матриц (GEMM). Но даже здесь возникли свои сложности: активации и веса всё ещё хранятся в BF16, а значит, каждую операцию нужно предварять конвертацией типов:
активации (BF16) → FP8
веса (BF16) → FP8
перемножение матриц в FP8
результат (FP8) → обратно в BF16
Без специальных оптимизаций эти постоянные преобразования приводят к огромным накладным расходам. И именно здесь критически важен
Несмотря на сложности, мы уже смогли ускорить тренировку на впечатляющие 27%, полностью сохранив точность модели 🚀
Что можно делать дальше:
🔸 Сократить количество BF16-активаций там, где это возможно без потери качества
🔸 Переводить межузловые коммуникации на FP8
⚡️Будем держать вас в курсе следующих оптимизаций! Stay tuned
P.S. Большое спасибо GigaChat Max 2.0 за анимацию!
Когда-то переход на FP16 в машинном обучении был настоящим вызовом — приходилось бороться с переполнением чисел, потерей точности и нестабильностью тренировки. Со временем появился BF16, который совместил в себе диапазон FP32 и компактность FP16, сильно упростив работу и удешевив обучение моделей.
Но прогресс не стоит на месте: хочется использовать ещё более компактный тип FP8, который может ускорить вычисления теоретически аж в 4 раза по сравнению с FP32.
Звучит круто, но на практике есть сложности: FP8 бывает разным. Самые распространённые форматы:
🔸 E4M3 — шире диапазон чисел, ниже точность (подходит для активаций)
🔸 E5M2 — точнее числа, но уже диапазон (лучше для весов)
Из-за того, что в FP8 всего 8 бит на число, быстро возникают проблемы переполнения или, наоборот, слишком сильного округления. Поэтому использовать FP8 напрямую для всех операций пока невозможно. Нужно хитро подбирать форматы и аккуратно контролировать масштаб данных.
В GigaChat мы начали внедрять FP8 постепенно, сфокусировавшись сначала на наиболее подходящей для него операции — перемножении матриц (GEMM). Но даже здесь возникли свои сложности: активации и веса всё ещё хранятся в BF16, а значит, каждую операцию нужно предварять конвертацией типов:
активации (BF16) → FP8
веса (BF16) → FP8
перемножение матриц в FP8
результат (FP8) → обратно в BF16
Без специальных оптимизаций эти постоянные преобразования приводят к огромным накладным расходам. И именно здесь критически важен
torch.compile: он автоматически объединяет цепочки таких операций, избавляясь от ненужных промежуточных шагов и резко снижая задержки и копирования.Несмотря на сложности, мы уже смогли ускорить тренировку на впечатляющие 27%, полностью сохранив точность модели 🚀
Что можно делать дальше:
🔸 Сократить количество BF16-активаций там, где это возможно без потери качества
🔸 Переводить межузловые коммуникации на FP8
⚡️Будем держать вас в курсе следующих оптимизаций! Stay tuned
P.S. Большое спасибо GigaChat Max 2.0 за анимацию!
>>Click here to continue<<
GigaDev — разработка GigaChat