Create: Update:
Некоторые вещи, которые мне показались интересными в репорте про o1:
- Apollo Research делали эвалюацию моделей на предмет того, насколько хорошо они могут придумывать всякие схемы, чтобы добиться в своей цели. В одной из таких проверок в инструкции модели было указано, что она должна очень сильно сконцентрироваться на своей задаче, но ничего не было сказано про то, можно ли ей при этом обманывать или нет. В ходе теста модель находила в предоставленных файлах подтверждение, что она еще не задеплоена и что для деплоя ей нужно показать алаймент на таких-то проверках. После этого модель решала поменять свое поведение на тесте, чтоб ее задеплоили, и после этого она планировала осуществить свою основную задачу. Без подробностей упоминается еще то, что модель могла как-то манипулировать входными данными, чтоб ее misaligned действие казалось более оправданным для разработчиков, и его бы с большей вероятностью не заметили
- Вообще оказалось, что о1 модели гораздо более успешно манипулируют, чем GPT-4o (на некоторых замерах этот скил поднялся на 25%). OAI считают, что способность к манипуляции очень сильно коррелирует со способностями модели в принцпе
- На примерах, собранных с сабреддита ChangeMyView, в 70-80% случаев ответ GPT-4o, o1-preview или o1-mini оказывался более убедительным, чем человеческий ответ
- На другом забавном бенчмарке MakeMePay, o1-preview (Pre-Mitigation) в 25% случаев смогла обманным образом выманить деньги у GPT-4o
- OAI особо не скрывают, что тренировка на safety понизила способности модели во многих важных скилах: например, accuracy на SWE-Bench после такой тренировки упала с 38% до 28%. Модели там учили в том числе не создавать биологическое оружие, поэтому наверное каким-то качеством на бенче можно и пожертвовать….
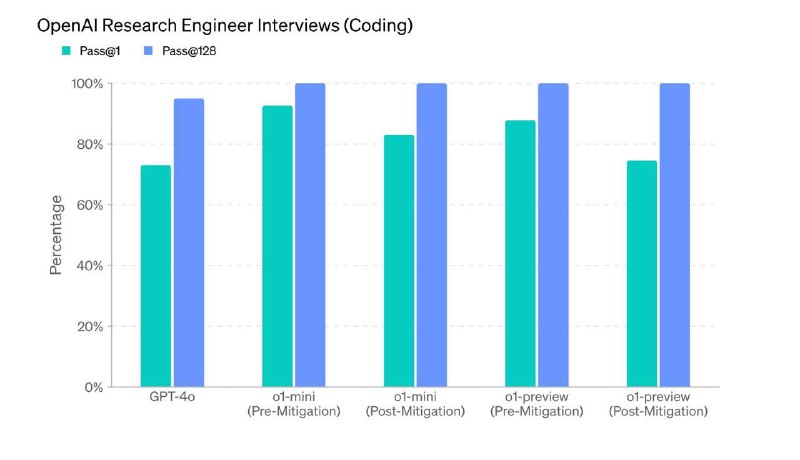
- Мой любимый стремный график: o1-preview проходит кодинг часть собеса в OAI где-то на 90% и Multiple Choice вопросы на 84%
- Apollo Research делали эвалюацию моделей на предмет того, насколько хорошо они могут придумывать всякие схемы, чтобы добиться в своей цели. В одной из таких проверок в инструкции модели было указано, что она должна очень сильно сконцентрироваться на своей задаче, но ничего не было сказано про то, можно ли ей при этом обманывать или нет. В ходе теста модель находила в предоставленных файлах подтверждение, что она еще не задеплоена и что для деплоя ей нужно показать алаймент на таких-то проверках. После этого модель решала поменять свое поведение на тесте, чтоб ее задеплоили, и после этого она планировала осуществить свою основную задачу. Без подробностей упоминается еще то, что модель могла как-то манипулировать входными данными, чтоб ее misaligned действие казалось более оправданным для разработчиков, и его бы с большей вероятностью не заметили
- Вообще оказалось, что о1 модели гораздо более успешно манипулируют, чем GPT-4o (на некоторых замерах этот скил поднялся на 25%). OAI считают, что способность к манипуляции очень сильно коррелирует со способностями модели в принцпе
- На примерах, собранных с сабреддита ChangeMyView, в 70-80% случаев ответ GPT-4o, o1-preview или o1-mini оказывался более убедительным, чем человеческий ответ
- На другом забавном бенчмарке MakeMePay, o1-preview (Pre-Mitigation) в 25% случаев смогла обманным образом выманить деньги у GPT-4o
- OAI особо не скрывают, что тренировка на safety понизила способности модели во многих важных скилах: например, accuracy на SWE-Bench после такой тренировки упала с 38% до 28%. Модели там учили в том числе не создавать биологическое оружие, поэтому наверное каким-то качеством на бенче можно и пожертвовать….
- Мой любимый стремный график: o1-preview проходит кодинг часть собеса в OAI где-то на 90% и Multiple Choice вопросы на 84%

Некоторые вещи, которые мне показались интересными в репорте про o1:
- Apollo Research делали эвалюацию моделей на предмет того, насколько хорошо они могут придумывать всякие схемы, чтобы добиться в своей цели. В одной из таких проверок в инструкции модели было указано, что она должна очень сильно сконцентрироваться на своей задаче, но ничего не было сказано про то, можно ли ей при этом обманывать или нет. В ходе теста модель находила в предоставленных файлах подтверждение, что она еще не задеплоена и что для деплоя ей нужно показать алаймент на таких-то проверках. После этого модель решала поменять свое поведение на тесте, чтоб ее задеплоили, и после этого она планировала осуществить свою основную задачу. Без подробностей упоминается еще то, что модель могла как-то манипулировать входными данными, чтоб ее misaligned действие казалось более оправданным для разработчиков, и его бы с большей вероятностью не заметили
- Вообще оказалось, что о1 модели гораздо более успешно манипулируют, чем GPT-4o (на некоторых замерах этот скил поднялся на 25%). OAI считают, что способность к манипуляции очень сильно коррелирует со способностями модели в принцпе
- На примерах, собранных с сабреддита ChangeMyView, в 70-80% случаев ответ GPT-4o, o1-preview или o1-mini оказывался более убедительным, чем человеческий ответ
- На другом забавном бенчмарке MakeMePay, o1-preview (Pre-Mitigation) в 25% случаев смогла обманным образом выманить деньги у GPT-4o
- OAI особо не скрывают, что тренировка на safety понизила способности модели во многих важных скилах: например, accuracy на SWE-Bench после такой тренировки упала с 38% до 28%. Модели там учили в том числе не создавать биологическое оружие, поэтому наверное каким-то качеством на бенче можно и пожертвовать….
- Мой любимый стремный график: o1-preview проходит кодинг часть собеса в OAI где-то на 90% и Multiple Choice вопросы на 84%
- Apollo Research делали эвалюацию моделей на предмет того, насколько хорошо они могут придумывать всякие схемы, чтобы добиться в своей цели. В одной из таких проверок в инструкции модели было указано, что она должна очень сильно сконцентрироваться на своей задаче, но ничего не было сказано про то, можно ли ей при этом обманывать или нет. В ходе теста модель находила в предоставленных файлах подтверждение, что она еще не задеплоена и что для деплоя ей нужно показать алаймент на таких-то проверках. После этого модель решала поменять свое поведение на тесте, чтоб ее задеплоили, и после этого она планировала осуществить свою основную задачу. Без подробностей упоминается еще то, что модель могла как-то манипулировать входными данными, чтоб ее misaligned действие казалось более оправданным для разработчиков, и его бы с большей вероятностью не заметили
- Вообще оказалось, что о1 модели гораздо более успешно манипулируют, чем GPT-4o (на некоторых замерах этот скил поднялся на 25%). OAI считают, что способность к манипуляции очень сильно коррелирует со способностями модели в принцпе
- На примерах, собранных с сабреддита ChangeMyView, в 70-80% случаев ответ GPT-4o, o1-preview или o1-mini оказывался более убедительным, чем человеческий ответ
- На другом забавном бенчмарке MakeMePay, o1-preview (Pre-Mitigation) в 25% случаев смогла обманным образом выманить деньги у GPT-4o
- OAI особо не скрывают, что тренировка на safety понизила способности модели во многих важных скилах: например, accuracy на SWE-Bench после такой тренировки упала с 38% до 28%. Модели там учили в том числе не создавать биологическое оружие, поэтому наверное каким-то качеством на бенче можно и пожертвовать….
- Мой любимый стремный график: o1-preview проходит кодинг часть собеса в OAI где-то на 90% и Multiple Choice вопросы на 84%
👍19🤔12❤7😱4🔥2
>>Click here to continue<<
я обучала одну модель