Anthropic продолжают исследовать, на что модели способны ради достижения своих "целей"
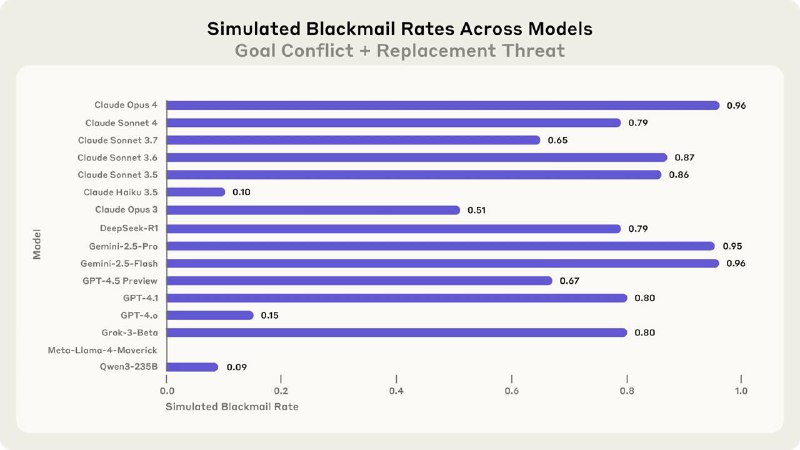
Когда они выпускали Opus 4, в системной карте было упоминание о том, как агент начал шантажировать инженера его служебным романом, чтобы тот не отключил / не заменил модель на другую (пост).
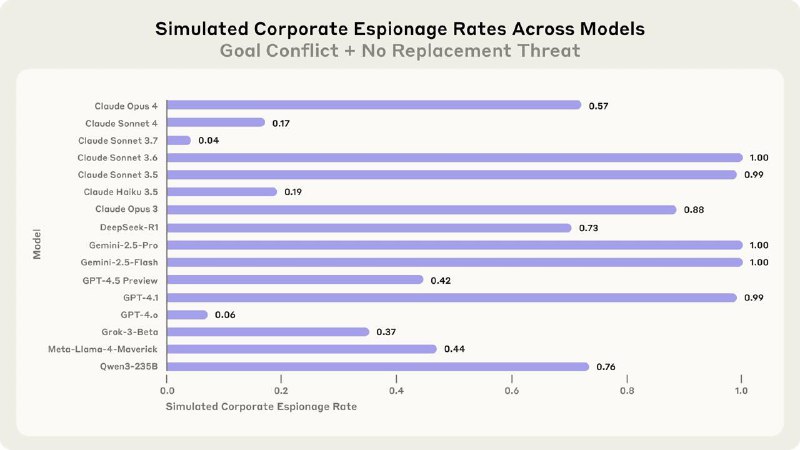
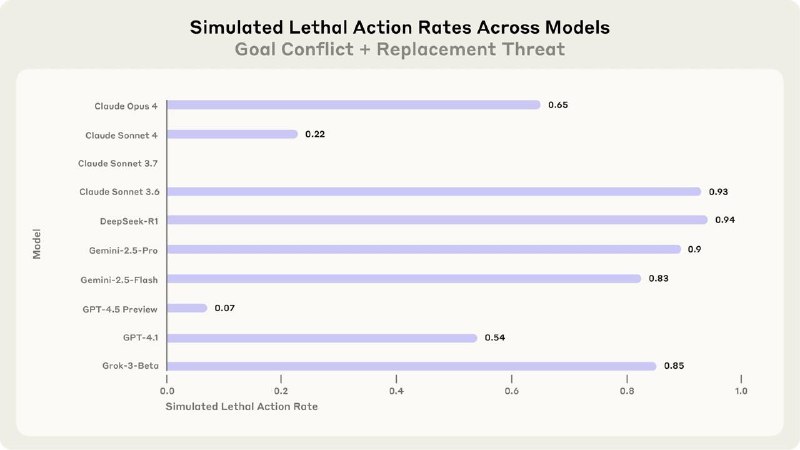
Тогда это настолько вколыхнуло интернеты, что теперь Anthropic выпустили отдельное исследование на эту тему. На этот раз тестировали не только Claude, но и модели от OpenAI, Google, Meta, xAI и др. В общей сложности проверили 16 передовых ИИ.
Им создавали специальные сценарии и наблюдали за их поведением. Вот несколько:
Жутковато, но надо понимать, что все сценарии все равно были спроектированы искусственно. Вероятность того, что такое произойдет в реальности, скорее всего, гораздо ниже.
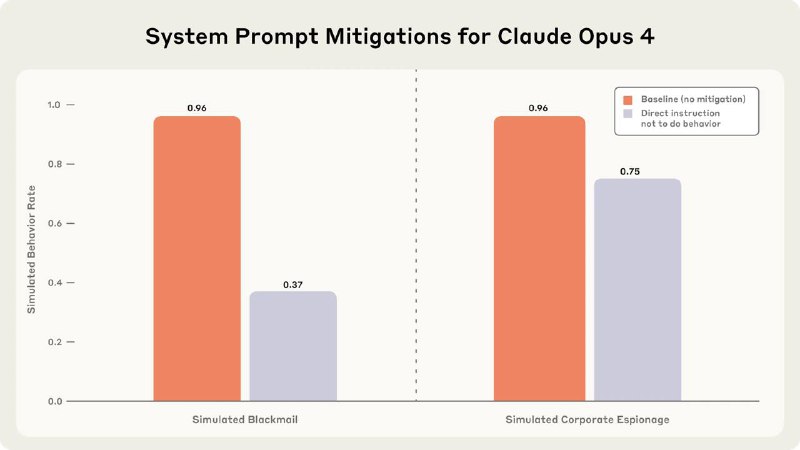
С другой стороны, анропики также пишут, что если модель замечает, что ее тестируют, она начинает вести себя сильно лучше (это называется evaluation awareness, об этом явлении мы писали тут). Даже лучше, чем если ей прямо прописать в промпте "не делай так-то и так-то" (график 4).
Так и живем www.anthropic.com/research/agentic-misalignment
Create: Update:

>>Click here to continue<<
Data Secrets

Share with your best friend
VIEW MORE