Иллюзия рассуждений: Apple выпустили честную статью про ограничения ризонинг-моделей
Мы уже привыкли, что если дать модели возможность "подумать" перед ответом (aka просто погенерировать некоторое количество черновых токенов), то она будет отвечать гораздо лучше по сравнению с моделями без ризонинга.
Но на самом деле ризонинг модели, их способности и масштабируемость изучены очень мало. Все, что мы видели, это графики "чем больше компьюта – тем лучше ответы", но это взгляд только с одной стороны, и, вообще говоря, о самой природе ризонинга мы знаем немного.
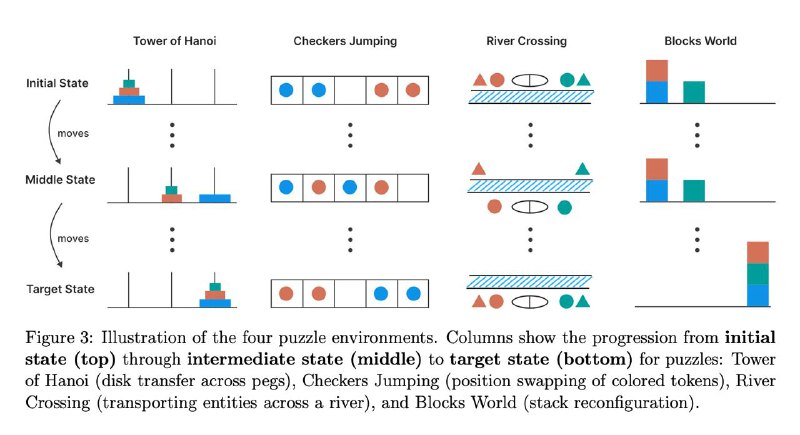
Apple решили немного развеять мифы вокруг рассуждений и провели простой эксперимент. Они взяли несколько головоломок, которые можно итерационно усложнять и стали сравнивать на них ризонинг модели с обычными.
Ну, например, Хайнойская башня. Для трех колец она решается довольно легко, для четырех сложнее, для десяти еще сложнее и тд (но вообще-то существует общий алгоритм). Так вот, итог:
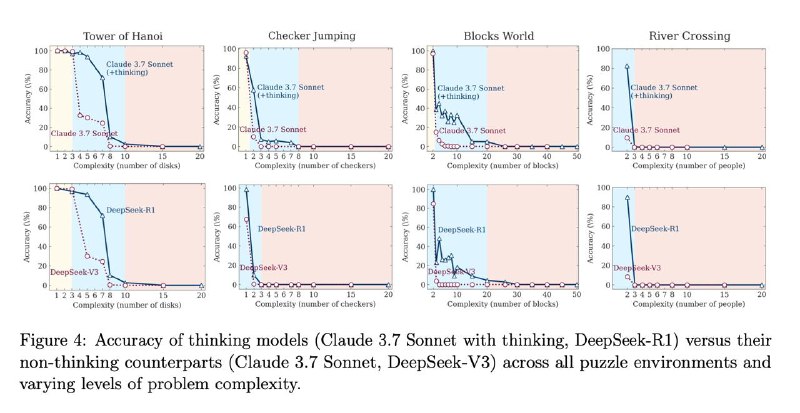
➖ На низкой сложности задач немыслящие LLM оказались лучше ризонинг-моделей. На средней сложности CoT действительно начинает давать преимущество, но на высокой и ризонеры, и обычные модели фейлятся полностью, вне зависимости от бюджета компьюта.➖ При этом на несложных задачах часто происходит overthinking: модель почти сразу доходит до правильного ответа, но не фиксирует его, не останавливается и зачем-то продолжает "думать", просто чтобы потратить бюджет ризонинга.➖ А на сложных задачах – наоборот. При приближении к критической сложности модели сокращают объём «think» токенов, хотя лимит не исчерпан – они просто устают думать раньше времени.➖ Даже когда модельке дают готовый общий алгоритм решения, её точность не растёт, и коллапс происходит в тех же точках сложности.➖ Ну и, плюс, рассуждения почему-то не генерализируются. На более известных головоломках модель еще как-то думает, а на менее известных, даже если они легче, рассуждения не помогают, и точность падает даже на низких уровнях.
Согласитесь, это местами контр-интуитивно и не совпадает с тем, как обычно позиционируют ризонинг-модели поставщики: того самого устойчивого масштабирования и ага-моментов не наблюдается.
И уж тем более такое поведение мало похоже на процесс мышления в привычном человеческом смысле. Видимо, AGI нам все-таки еще долго не видать.
machinelearning.apple.com/research/illusion-of-thinking