How much do language models memorize? Новое исследование от Meta FAIR, Google DeepMind и NVIDIA
Задумывались когда-нибудь, сколько данных может запомнить модель с определенным количеством параметров? А сколько конкретно информации может выучить один параметр? А сколько информации он может обобщить?
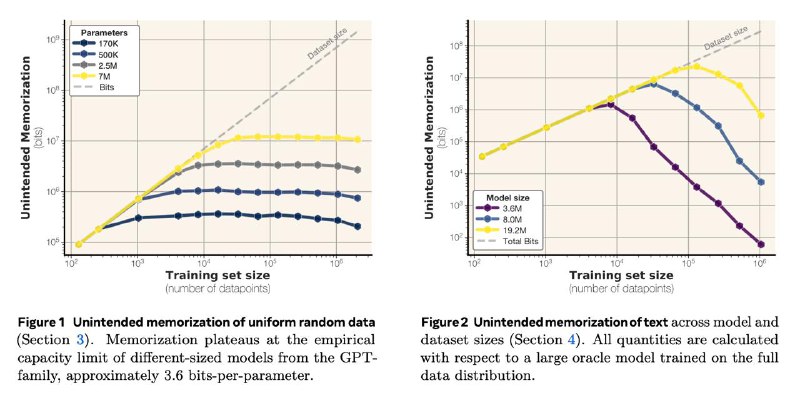
Кажется, что посчитать это очень сложно или даже невозможно, но вот у ученых из этой статьи получилось: каждый параметр языковой модели способен запомнить примерно 3.6 бит информации. О том, как это посчитали – ниже.
Сразу дисклеймер: до этого были и другие статьи на эту тему, но там запоминание определялось просто тем, может ли модель воспроизвести определенный кусок трейна. На самом же деле все сложнее, и в этой работе подход не такой наивный.
Обе модели пропускают один и тот же тренировочный фрагмент через процедуру предсказания и вычисляют вероятности каждого токена. Если вторая модель даёт более высокие вероятности (то есть «тратит» на их декодинг меньше бит, чем референсная), она экономит относительно референсной модели определённое число бит. Сумма сэкономленных бит по всем фрагментам и есть общий объём выученной информации.
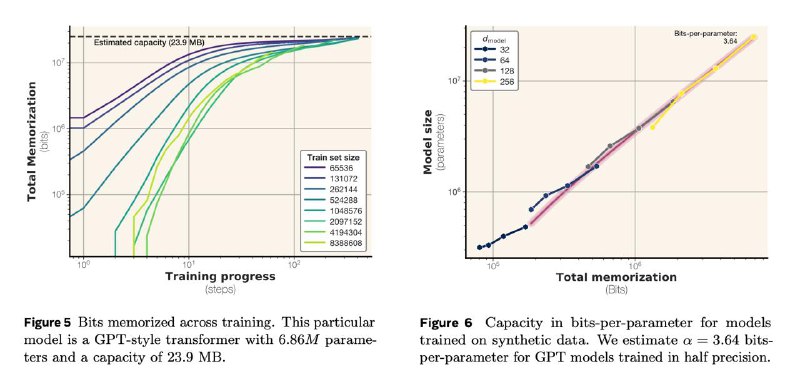
Вот так и получилось число 3.6 бит/параметр.
Самое важное, что этот показатель дает возможность четко определить момент перехода запоминания в обобщение: он происходит, когда объём данных в битах примерно равен общей ёмкости модели. И да, экспериментально это сходится: как раз на этом объеме данных тестовый лосс начинает резко падать. Это, кстати, часто называют грокингом.
Красота, как она есть arxiv.org/abs/2505.24832
Create: Update:

>>Click here to continue<<
Data Secrets

Share with your best friend
VIEW MORE