DeepMath-103K — это новый мощный набор задач для обучения больших языковых моделей (LLMs) математическому рассуждению на высоком уровне сложности с помощью reinforcement learning (RL).
📦 Что в наборе?
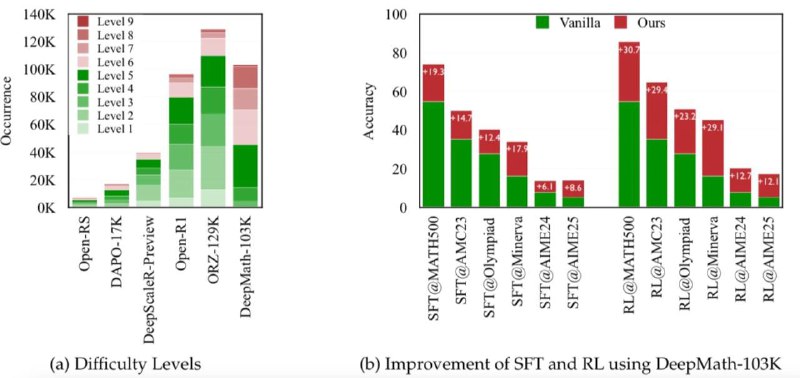
103 000+ задач уровня сложности 5–9 (от среднего до продвинутого уровня).
Каждая задача включает:
📌 Верифицируемый ответ — важно для обучения с подкреплением.
🧪 3 решения, сгенерированных моделью R1 — для обучения с учителем или дистилляции.
Полная очистка от утечек данных (decontaminated) — можно безопасно использовать на бенчмарках.
📊 Почему это важно?
Модели, обученные на DeepMath-103K, показывают существенный прирост точности на сложных математических задачах и бенчмарках (MATH, GSM8K, MiniF2F и др.).
🛠 Применение:
Fine-tuning моделей (например, GPT, LLaMA) для математического reasoning.
RLHF (reinforcement learning with human feedback) и self-improvement.
Дистилляция сильных моделей в более компактные.
@data_math
Create: Update:

>>Click here to continue<<
Математика Дата саентиста
Share with your best friend
VIEW MORE