Create: Update:
Как померить эффективность программиста в деньгах?
Периодически со мной делится интересными рассуждениями мой бывший соведущий подкаста Артём Цацин. И вот одна из историй зацепила меня настолько, что хочу поделиться ходом мысли здесь, в канале.
Представьте себе классическую ситуацию: Вася и Петя. Оба сделали задачу. Код сдали. Вася — быстро, дерзко, но его код через месяц никто поддерживать не может. А Петя — аккуратно, долго, но стабильно. Код живёт два года без багов.
На собеседовании вы хотите больше таких, как Петя. И платить им готовы больше. Но вот проблема — как понять, кто перед вами? Вася или Петя? Книг, курсов и статей — море. Но по сути всё сводится к тому, что надо просто смотреть на результат и надеяться, что вас не обманут.
А теперь к сути. Тёма посмотрел на свежую диаграмму со стоимостью reasoning у разных LLM — и его осенило.
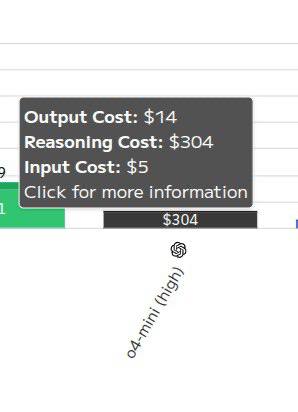
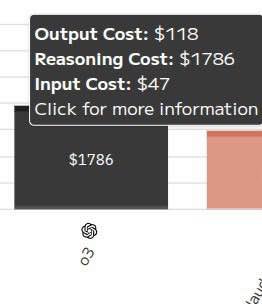
Например, посмотрите на модель o4: на вывод (output) уходит $14, а на reasoning — $304. В двадцать раз больше! Аналогично у o3: $118 на вывод и $1786 — просто чтобы «подумать». И это же оно. Это и есть Петя. Он просто много думает прежде чем дать ответ. И вы платите ему не за «код», а за ту самую невидимую работу до.
А если вы скажете модели: не думай, давай сразу ответ — качество резко падает. Просто потому что глубины нет. По сути, это тот самый Вася.
И это интересно — потому что, наконец, появляется прямая корреляция между затратами на «подумать» и качеством. Впервые вы можете как менеджер буквально «купить» себе рассуждение. Заставьте Петю думать 32k токенов на задачу — и результат будет лучше.
Модели, в отличие от программистов, не бастуют. Хотите больше думать — платите больше денег. Хотите меньше — получите Васю. И баги. Получается, у нас впервые появился идеальный программист — стоимость которого прямо зависит от того, насколько глубоко он думает. И при этом он не устает, не выгорает и не берёт отпуск.
Хотите Петю — включайте reasoning. Хотите дешево и сердито — не жалуйтесь потом, что всё багами покрыто.
Периодически со мной делится интересными рассуждениями мой бывший соведущий подкаста Артём Цацин. И вот одна из историй зацепила меня настолько, что хочу поделиться ходом мысли здесь, в канале.
Представьте себе классическую ситуацию: Вася и Петя. Оба сделали задачу. Код сдали. Вася — быстро, дерзко, но его код через месяц никто поддерживать не может. А Петя — аккуратно, долго, но стабильно. Код живёт два года без багов.
На собеседовании вы хотите больше таких, как Петя. И платить им готовы больше. Но вот проблема — как понять, кто перед вами? Вася или Петя? Книг, курсов и статей — море. Но по сути всё сводится к тому, что надо просто смотреть на результат и надеяться, что вас не обманут.
А теперь к сути. Тёма посмотрел на свежую диаграмму со стоимостью reasoning у разных LLM — и его осенило.
Например, посмотрите на модель o4: на вывод (output) уходит $14, а на reasoning — $304. В двадцать раз больше! Аналогично у o3: $118 на вывод и $1786 — просто чтобы «подумать». И это же оно. Это и есть Петя. Он просто много думает прежде чем дать ответ. И вы платите ему не за «код», а за ту самую невидимую работу до.
А если вы скажете модели: не думай, давай сразу ответ — качество резко падает. Просто потому что глубины нет. По сути, это тот самый Вася.
И это интересно — потому что, наконец, появляется прямая корреляция между затратами на «подумать» и качеством. Впервые вы можете как менеджер буквально «купить» себе рассуждение. Заставьте Петю думать 32k токенов на задачу — и результат будет лучше.
Модели, в отличие от программистов, не бастуют. Хотите больше думать — платите больше денег. Хотите меньше — получите Васю. И баги. Получается, у нас впервые появился идеальный программист — стоимость которого прямо зависит от того, насколько глубоко он думает. И при этом он не устает, не выгорает и не берёт отпуск.
Хотите Петю — включайте reasoning. Хотите дешево и сердито — не жалуйтесь потом, что всё багами покрыто.

Forwarded from Андрей Смирнов | Викенд в IT
Как померить эффективность программиста в деньгах?
Периодически со мной делится интересными рассуждениями мой бывший соведущий подкаста Артём Цацин. И вот одна из историй зацепила меня настолько, что хочу поделиться ходом мысли здесь, в канале.
Представьте себе классическую ситуацию: Вася и Петя. Оба сделали задачу. Код сдали. Вася — быстро, дерзко, но его код через месяц никто поддерживать не может. А Петя — аккуратно, долго, но стабильно. Код живёт два года без багов.
На собеседовании вы хотите больше таких, как Петя. И платить им готовы больше. Но вот проблема — как понять, кто перед вами? Вася или Петя? Книг, курсов и статей — море. Но по сути всё сводится к тому, что надо просто смотреть на результат и надеяться, что вас не обманут.
А теперь к сути. Тёма посмотрел на свежую диаграмму со стоимостью reasoning у разных LLM — и его осенило.
Например, посмотрите на модель o4: на вывод (output) уходит $14, а на reasoning — $304. В двадцать раз больше! Аналогично у o3: $118 на вывод и $1786 — просто чтобы «подумать». И это же оно. Это и есть Петя. Он просто много думает прежде чем дать ответ. И вы платите ему не за «код», а за ту самую невидимую работу до.
А если вы скажете модели: не думай, давай сразу ответ — качество резко падает. Просто потому что глубины нет. По сути, это тот самый Вася.
И это интересно — потому что, наконец, появляется прямая корреляция между затратами на «подумать» и качеством. Впервые вы можете как менеджер буквально «купить» себе рассуждение. Заставьте Петю думать 32k токенов на задачу — и результат будет лучше.
Модели, в отличие от программистов, не бастуют. Хотите больше думать — платите больше денег. Хотите меньше — получите Васю. И баги. Получается, у нас впервые появился идеальный программист — стоимость которого прямо зависит от того, насколько глубоко он думает. И при этом он не устает, не выгорает и не берёт отпуск.
Хотите Петю — включайте reasoning. Хотите дешево и сердито — не жалуйтесь потом, что всё багами покрыто.
Периодически со мной делится интересными рассуждениями мой бывший соведущий подкаста Артём Цацин. И вот одна из историй зацепила меня настолько, что хочу поделиться ходом мысли здесь, в канале.
Представьте себе классическую ситуацию: Вася и Петя. Оба сделали задачу. Код сдали. Вася — быстро, дерзко, но его код через месяц никто поддерживать не может. А Петя — аккуратно, долго, но стабильно. Код живёт два года без багов.
На собеседовании вы хотите больше таких, как Петя. И платить им готовы больше. Но вот проблема — как понять, кто перед вами? Вася или Петя? Книг, курсов и статей — море. Но по сути всё сводится к тому, что надо просто смотреть на результат и надеяться, что вас не обманут.
А теперь к сути. Тёма посмотрел на свежую диаграмму со стоимостью reasoning у разных LLM — и его осенило.
Например, посмотрите на модель o4: на вывод (output) уходит $14, а на reasoning — $304. В двадцать раз больше! Аналогично у o3: $118 на вывод и $1786 — просто чтобы «подумать». И это же оно. Это и есть Петя. Он просто много думает прежде чем дать ответ. И вы платите ему не за «код», а за ту самую невидимую работу до.
А если вы скажете модели: не думай, давай сразу ответ — качество резко падает. Просто потому что глубины нет. По сути, это тот самый Вася.
И это интересно — потому что, наконец, появляется прямая корреляция между затратами на «подумать» и качеством. Впервые вы можете как менеджер буквально «купить» себе рассуждение. Заставьте Петю думать 32k токенов на задачу — и результат будет лучше.
Модели, в отличие от программистов, не бастуют. Хотите больше думать — платите больше денег. Хотите меньше — получите Васю. И баги. Получается, у нас впервые появился идеальный программист — стоимость которого прямо зависит от того, насколько глубоко он думает. И при этом он не устает, не выгорает и не берёт отпуск.
Хотите Петю — включайте reasoning. Хотите дешево и сердито — не жалуйтесь потом, что всё багами покрыто.
>>Click here to continue<<
Плохой Project Артём Арюткин