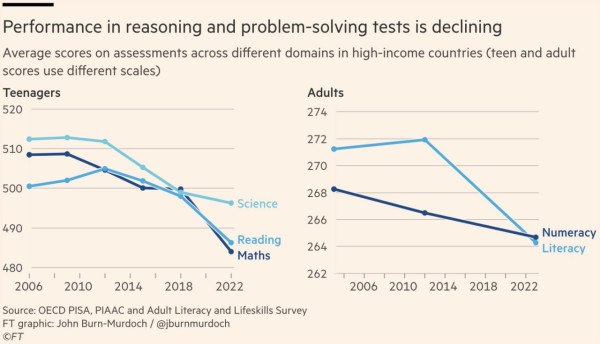
Опубликовано очередное обновление курса "Системная инженерия", в этой версии переписан раздел "5. Эволюционная архитектура", всего переписано уже 70% курса. Чего я жду для использования LLM: чтобы писать, уже не жду, а пользую, а чтобы вытащить это для студентов — удобного фреймворка RAG, и потихоньку отслеживаю там происходящее. В четверг прошла вторая тренировка по мантре системного мышления, объекты разной природы — но главный вопрос в причинно-следственном объяснении, зачем нужна наша система, ибо ну не хотят люди привязывать свой проект к целевой системе, очень уж это контринтуитивно! RL в causality ladder — это вторая ступенька, do-calculus, а там ещё третья ступенька есть causal reinforcement learning, рассуждаю на эту тему и даю три темы, для которых это всё важно лично для меня. Схемы Парето-границ для LLM сравниваю с такими же для людей, бенчмаркинг интеллектов ведь сильно продвинулся — вот и людей надо тоже бенчмаркать, тоже по Парето. Мы живём в удивительное время, когда человечество в развитых странах тупеет на глазах (пруф в картинке), а нежить умнеет -- в целом же пока баланс: что население мозгами сдаёт, нежить подхватывает и даже с опережением, жизнь становится лучше.
https://ailev.livejournal.com/1757388.html (11Кзнаков)

>>Click here to continue<<