FlexTok - метод токенизации изображений, который преобразует 2D-изображения в упорядоченные 1D-последовательности переменной длины.
Его цель - сократить объем данных, необходимых для обучения генеративных моделей, и при этом оставить достаточную информацию для качественной реконструкции и генерации.
В отличие от традиционных подходов, где число токенов фиксировано и зависит только от размера изображения, FlexTok подстраивается под сложность контента: простейшая сцена может кодироваться несколькими токенами, а сложная - десятками и сотнями .
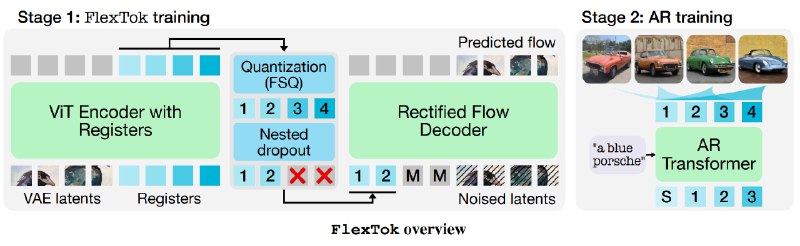
FlexTok, это по сути, пайплайн из 3 компонентов: ViT‑энкодер, квантование регистров и маскирование внимания:
ViT‑энкодер с набором «регистровых» токенов читает латентные представления VAE‑GAN и конденсирует их в 1D-последовательность до 256 регистров .
Затем, с помощью FSQ‑квантования, каждый регистр дискретизируется в код из заранее определенного словаря размером ~64 000.
На этом этапе применяется "nested dropout": во время обучения случайно обрезаются последние токены, чтобы модель научилась упорядочивать информацию от грубых форм к деталям.
Параллельно применяется авторегрессионная маска внимания: каждый токен в цепочке видит только те, что были до него, и не знает о тех, что идут после. Это заставляет модель генерировать изображения шаг за шагом, от первого токена к последнему, и упрощает ей задачу прогнозирования следующих элементов.
Декодер в FlexTok - это модель rectified flow, которая на вход берет укороченные токены и слегка зашумленные латенты VAE и учится предсказывать тот шум, который нужно убрать, чтобы вернуть исходное представление.
Чтобы обучение шло быстрее и давало более точные результаты, добавляют REPA‑Loss: он сравнивает промежуточные признаки с векторами из DINOv2‑L. Благодаря этому даже при очень жесткой компрессии (от 1 до 256 токенов), FlexTok успешно восстанавливает детали изображения.
FlexTok легко встраивается в текстово‑ориентированные модели и может улучшить соответствие изображения описанию, даже если число токенов меняется. К тому же его адаптивная токенизация применима не только к картинкам, но и к аудио или видео.
@ai_machinelearning_big_data
#AI #ML #Tokenizer #Flextok #Apple
Create: Update:

>>Click here to continue<<
Machinelearning


Share with your best friend
VIEW MORE