Salesforce AI Research выпустила BLIP3-o, набор полностью открытых унифицированных мультимодальных моделей, которые могут как понимать, так и генерировать изображения.
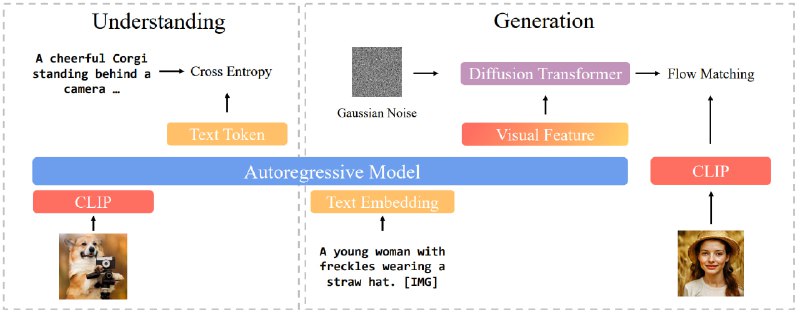
Под капотом у BLIP3-o гибрид авторегрессионной модели (генерирует промежуточные семантические признаки) и диффузионного трансформера (он превращает их в изображения).
В ходе работы разработчики провели ряд экспериментов для выбора оптимальной стратеги для архитектуры и обучения. Апробации гипотез показали, что использование CLIP работает эффективнее, чем традиционный VAE.
CLIP создает более компактные и информативные представления, что ускоряет обучение и улучшает качество генерируемых изображений. А flow matching лучше , чем подход с использованием среднеквадратичной ошибки (MSE): инференс в итоге более разнообразный и визуально качественный.
Наилучшие результаты обучения показал подход, при котором модель сначала обучают понимать изображения, а затем замораживают эти навыки, переключаясь на обучение генерации картинок.
На основе этих принципов и были созданы модели BLIP3-o 8B и BLIP3-o 4B.
В оценках по эталонным тестам BLIP3-o 8B набрала 1682.6 на MME-P, 50.6 на MMMU и 0.84 на GenEval. Исследование с оценкой человеком, сравнивающее BLIP3-o с Janus Pro, показало, что BLIP3-o лучше как по визуальному качеству, так и по соответствию промпту.
В будущем Salesforce планирует расширить возможности модели: редактирование существующих изображений, поддержка визуальных диалогов и пошаговая генерация.
@ai_machinelearning_big_data
#AI #ML #MMLM #BLIP3o #Salesforce
Create: Update:

>>Click here to continue<<
Machinelearning


Share with your best friend
VIEW MORE