Create: Update:
Microsoft Research представила KBLaM - архитектуру, которая решает ключевую проблему LLM — добавление новых внешних знаний. В отличие от традиционных методов файнтюна и RAG, KBLaM кодирует новые для LLM структурированные данные в виде векторных пар «ключ-значение», встраивая их напрямую в слои внимания модели. Это позволяет избежать дорогостоящего дообучения и построение дополнительных модулей, сохраняя линейную масштабируемость даже для баз знаний в 10 000 триплетов.
В KBLaM триплет — это структурированный элемент знания, состоящий из трех компонентов: сущности, свойства и значения. Например, в утверждении «Москва — столица России» сущностью выступает «Москва», свойством — «столица», а значением — «Россия».
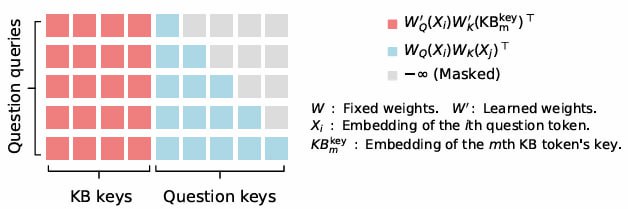
В основе KBLaM - «прямоугольный механизм внимания»: языковые токены взаимодействуют с токенами знаний, но не наоборот. Такая структура сокращает вычислительные затраты до линейных, позволяя обрабатывать эквивалент 200 тыс. токенов на одном GPU. При этом модель динамически обновляет знания без пересчёта всей базы — достаточно изменить один триплет.
Эксперименты с KBLaM показали, что он не только эффективен, но и прозрачен: веса внимания визуализируют, какие факты использует модель. Например, при запросе о медицинском диагнозе высокие оценки внимания к соответствующим триплетам снижают риск «галлюцинаций», при этом, если ответ на запрос лежит вне базы знаний, модель отказывается на него отвечать.
Как заявляют авторы, KBLaM — не просто шаг к умным LLM, а мост между обученными на базовых знаниях моделями и реальным миром, где знания постоянно обновляются.
В опубликованном на Github коде для применения KBLaM поддерживаются модели с HF:
и эмбединги для генерации базы знаний:
⚠️ Чтобы добавить поддержку других моделей, необходимо отредактировать скрипты обработки моделей и включить в них адаптер, подобный
llama_model.py в src/kblam/models.@ai_machinelearning_big_data
#AI #ML #LLM #MicrosoftResearch #KBLaM