Create: Update:
4 advanced attention mechanisms you should know:
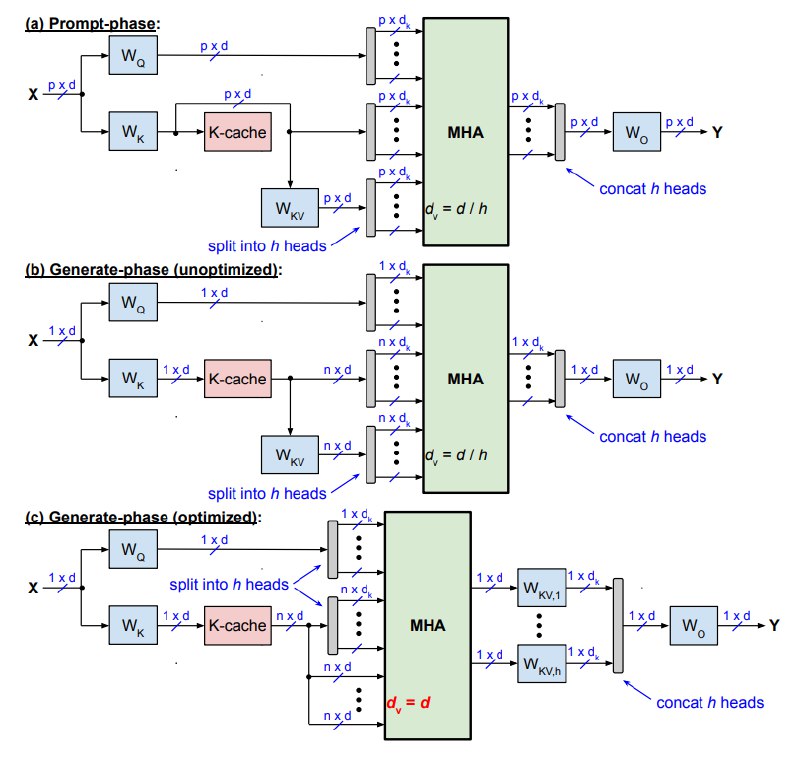
• Slim attention — 8× less memory, 5× faster generation by storing only K from KV pairs and recomputing V.
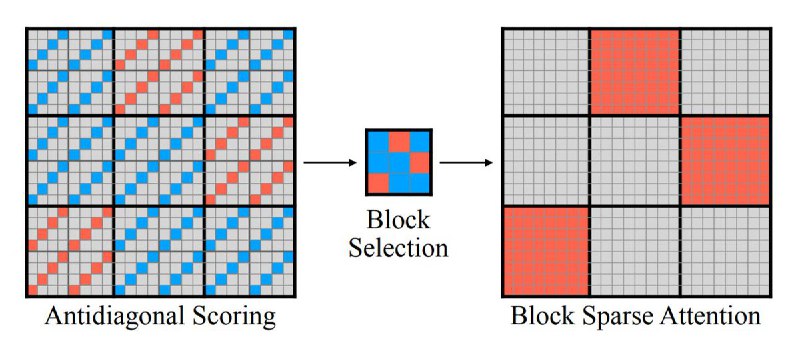
• XAttention — 13.5× speedup on long sequences via "looking" at the sum of values along diagonal lines in the attention matrix.
• Kolmogorov-Arnold Attention, KArAt — Adaptable attention with learnable activation functions using KANs instead of softmax.
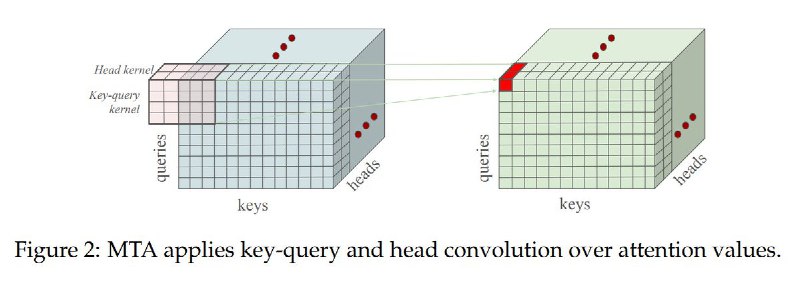
• Multi-token attention (MTA) — Lets the model consider groups of nearby words together for smarter long-context handling.
Read the overview of them in our free article on https://huggingface.co/blog/Kseniase/attentions
https://hottg.com/DataScienceM