Create: Update:
Visual-ARFT: открытый метод обучения AI-агентов обходит GPT-4o в мультимодальных задачах и снижает затраты на обучение на 88%
Исследователи обучали модель Qwen2.5-VL двум сценариям:
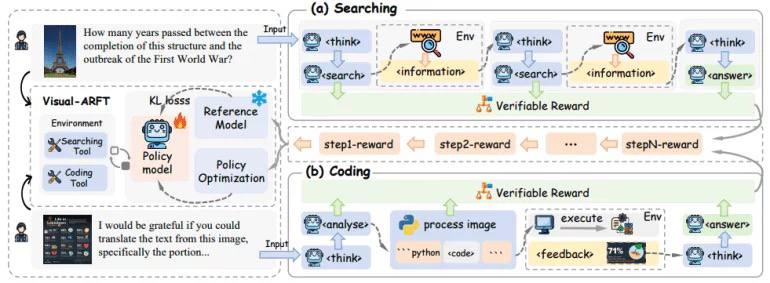
Агентный поиск: модель планирует, декомпозирует исходную задачу и извлекает информацию из внешних источников для ответа на сложные мультимодальные многошаговые VQA вопросы.
Агентное программирование: модель рассуждает о задаче, пишет и выполняет код для обработки изображений и решения сложных задач визуального анализа.
Visual-ARFT использует модульную систему верифицируемых вознаграждений:
Format Reward учит соблюдать четкий формат выходных данных, включая теги
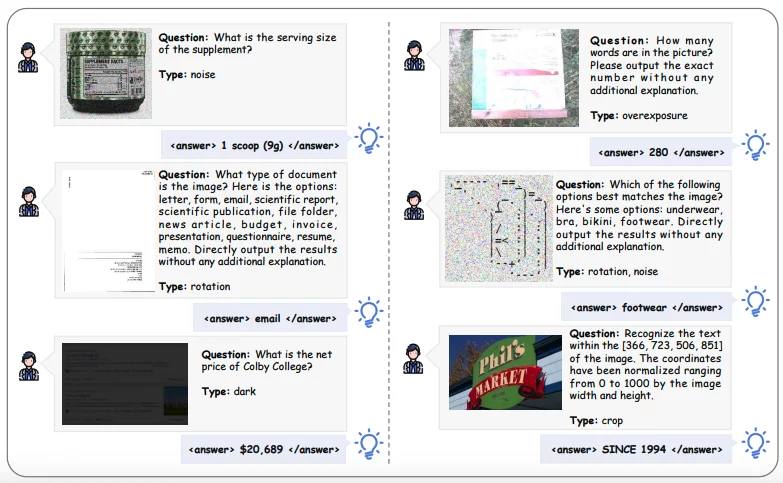
Accuracy Rewards оценивают качество ответов, используя F1-score, оценивая семантическое сходство поисковых запросов и выполнимость сгенерированного кода.
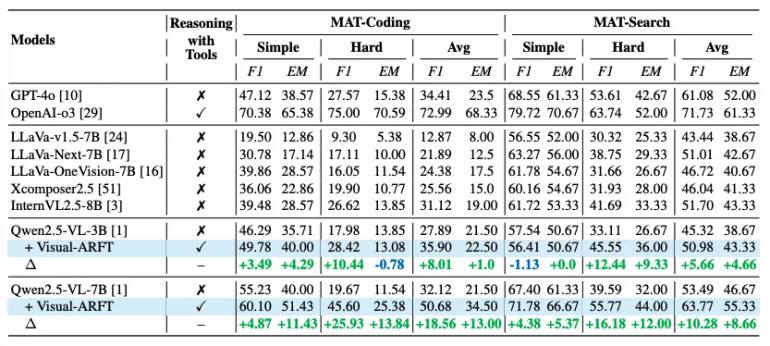
На MAT-Coding модель Qwen2.5-VL-7B с Visual-ARFT достигает улучшений +18.56% F1 и +13.00% EM по сравнению с базовой версией, превосходя GPT-4o.
На MAT-Search та же модель демонстрирует прирост +10.28% F1 и +8.66% EM.
Код доступен на Github.
#Stateoftheart
Исследователи обучали модель Qwen2.5-VL двум сценариям:
Агентный поиск: модель планирует, декомпозирует исходную задачу и извлекает информацию из внешних источников для ответа на сложные мультимодальные многошаговые VQA вопросы.
Агентное программирование: модель рассуждает о задаче, пишет и выполняет код для обработки изображений и решения сложных задач визуального анализа.
Visual-ARFT использует модульную систему верифицируемых вознаграждений:
Format Reward учит соблюдать четкий формат выходных данных, включая теги
<think>, <search>, <code> и <answer>. Это стимулирует структурированное пошаговое рассуждение и корректное использование инструментов.Accuracy Rewards оценивают качество ответов, используя F1-score, оценивая семантическое сходство поисковых запросов и выполнимость сгенерированного кода.
На MAT-Coding модель Qwen2.5-VL-7B с Visual-ARFT достигает улучшений +18.56% F1 и +13.00% EM по сравнению с базовой версией, превосходя GPT-4o.
На MAT-Search та же модель демонстрирует прирост +10.28% F1 и +8.66% EM.
Код доступен на Github.
#Stateoftheart

Forwarded from Neurohive - Нейронные сети, AI, ML, DL
Visual-ARFT: открытый метод обучения AI-агентов обходит GPT-4o в мультимодальных задачах и снижает затраты на обучение на 88%
Исследователи обучали модель Qwen2.5-VL двум сценариям:
Агентный поиск: модель планирует, декомпозирует исходную задачу и извлекает информацию из внешних источников для ответа на сложные мультимодальные многошаговые VQA вопросы.
Агентное программирование: модель рассуждает о задаче, пишет и выполняет код для обработки изображений и решения сложных задач визуального анализа.
Visual-ARFT использует модульную систему верифицируемых вознаграждений:
Format Reward учит соблюдать четкий формат выходных данных, включая теги
Accuracy Rewards оценивают качество ответов, используя F1-score, оценивая семантическое сходство поисковых запросов и выполнимость сгенерированного кода.
На MAT-Coding модель Qwen2.5-VL-7B с Visual-ARFT достигает улучшений +18.56% F1 и +13.00% EM по сравнению с базовой версией, превосходя GPT-4o.
На MAT-Search та же модель демонстрирует прирост +10.28% F1 и +8.66% EM.
Код доступен на Github.
#Stateoftheart
Исследователи обучали модель Qwen2.5-VL двум сценариям:
Агентный поиск: модель планирует, декомпозирует исходную задачу и извлекает информацию из внешних источников для ответа на сложные мультимодальные многошаговые VQA вопросы.
Агентное программирование: модель рассуждает о задаче, пишет и выполняет код для обработки изображений и решения сложных задач визуального анализа.
Visual-ARFT использует модульную систему верифицируемых вознаграждений:
Format Reward учит соблюдать четкий формат выходных данных, включая теги
<think>, <search>, <code> и <answer>. Это стимулирует структурированное пошаговое рассуждение и корректное использование инструментов.Accuracy Rewards оценивают качество ответов, используя F1-score, оценивая семантическое сходство поисковых запросов и выполнимость сгенерированного кода.
На MAT-Coding модель Qwen2.5-VL-7B с Visual-ARFT достигает улучшений +18.56% F1 и +13.00% EM по сравнению с базовой версией, превосходя GPT-4o.
На MAT-Search та же модель демонстрирует прирост +10.28% F1 и +8.66% EM.
Код доступен на Github.
#Stateoftheart
>>Click here to continue<<
Data Science by ODS.ai 🦜