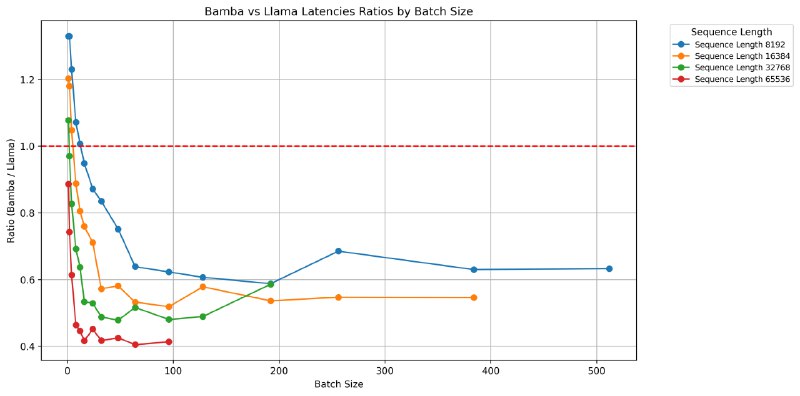
Bamba-9B - модель, разработанная IBM, Princeton, CMU и UIUC на основе полностью открытых данных. Модель демонстрирует улучшение пропускной способности в 2.5 раза и снижение задержки инференса в 2 раза по сравнению с Transformers в vLLM. Bamba-9B доступна для использования в HF Transformers, vLLM, TRL и llama.cpp.
Bamba-9B использует уникальный распределенный, не сохраняющий состояние data loader, обеспечивающий бесшовное возобновление работы, автоматическое масштабирование, потоковую передачу данных с zero-overhead for shuffling.
Модель основана на архитектуре NVIDIA hybrid Mamba2, но с некоторыми изменениями. Bamba-9B имеет 32 слоя, из которых 3 полноценных слоя внимания и 29 слоев Mamba2, в то время как NVIDIA hybrid Mamba2 имеет 29 слоев, из которых 4 слоя внимания и 25 слоев Mamba2.
Bamba-9B была обучена на 2.2T токенов с датасетом Dolma v1.7 на первом этапе и FineWeb-edu и Cosmopedia на втором.
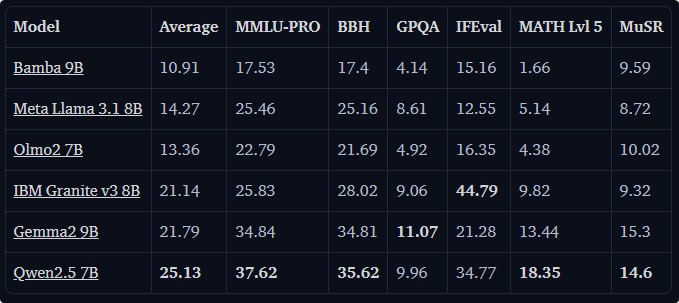
По проведенным замерам, средняя производительность Bamba-9B почти сравнима с Llama 3.1 8B (45.53 против 44.68), при том что Llama 3.1 8B была обучена на 7x большем объеме данных.
Bamba-9B превзошла Olmo 7B, обученную на идентичном количестве токенов и наборах данных. В сравнении с другими моделями на базе Mamba/Mamba2, Bamba-9B показывает хорошие результаты, при этом обеспечивая значительное улучшение (до 5x) эффективности логического вывода.llm-compressor версия Bamba 9Bllm-compressor версия Bamba 9B 2Тllm-compressor версия Bamba 9B 1.8Т
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("ibm-fms/Bamba-9B")
tokenizer = AutoTokenizer.from_pretrained("ibm-fms/Bamba-9B")
message = ["Mamba is a snake with following properties "]
inputs = tokenizer(message, return_tensors='pt', return_token_type_ids=False)
response = model.generate(**inputs, max_new_tokens=64)
print(tokenizer.batch_decode(response, skip_special_tokens=True)[0])
@ai_machinelearning_big_data
#AI #ML #LLM #Bamba #IBM